In the rapidly evolving landscape of artificial intelligence, enterprise leaders face a critical challenge: how to harness cutting-edge AI capabilities without breaking the bank or compromising on performance. Enter DeepSeek-V3 – a game-changing language model that’s about to rewrite the rules of enterprise AI adoption. DeepSeek-V3 is a groundbreaking large language model with openly available weights, representing a fundamental shift in the AI landscape. With its innovative design and exceptional performance, it is capturing the attention of both AI researchers and enterprise users alike.
Note: In AI, ‘open source’ requires public access to model weights, training code, datasets, and a permissive license for full transparency and reproducibility, while ‘open weights’ refers only to releasing model weights—even with a permissive license—which limits the ability to audit, modify, or rebuild the model from scratch.
Why Should Business Leaders Care?
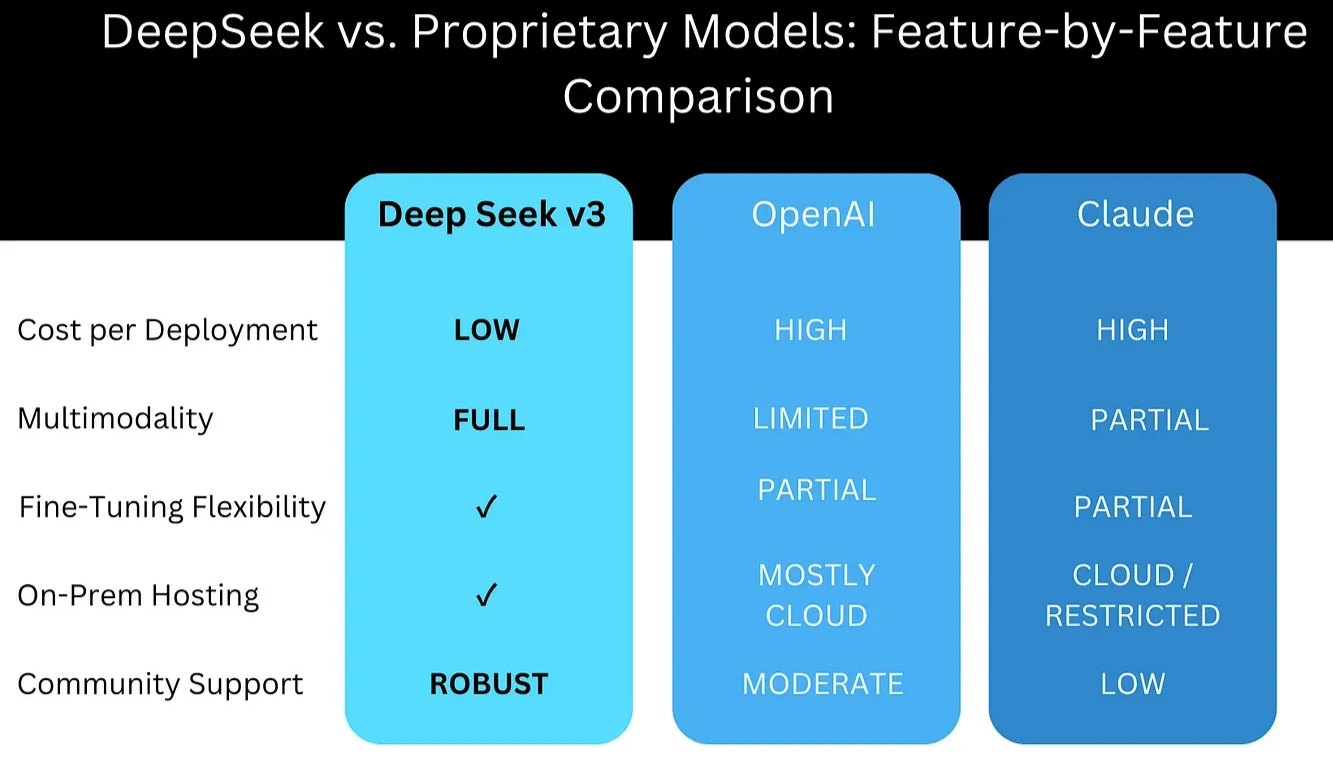
DeepSeek-V3 introduces an approach to enterprise AI that significantly reduces costs while maintaining high performance. Several key factors make this model particularly relevant for businesses:
- Lower Computational Costs – DeepSeek-V3’s Mixture-of-Experts (MoE) architecture selectively activates only the most relevant model components for a given task, reducing processing costs by approximately 95% compared to dense models that activate all parameters at once.
- Performance Comparable to Larger Models – Despite its efficiency, DeepSeek-V3 achieves state-of-the-art results in coding tasks, mathematical reasoning, and general NLP benchmarks, demonstrating that reduced computational cost does not necessarily mean reduced capability.
- Flexibility and Customization – As a model with open weights, DeepSeek-V3 allows enterprises to fine-tune, adapt, and deploy AI systems with greater control than closed-source alternatives, which keep their weights proprietary. This provides an opportunity for domain-specific optimizations without reliance on external API providers.
- Lower Training and Inference Costs – The model was trained for $5.6 million, a fraction of the cost of models like GPT-4, which require $50+ million. Its efficient design also leads to reduced inference costs, making deployment more accessible for a broader range of businesses.
The Enterprise AI Dilemma
For years, advanced AI has been a luxury reserved for tech giants. Deploying state-of-the-art language models meant:
- Astronomical infrastructure investments
- Prohibitive per-token processing costs
- Complex integration challenges
- Limited customization options
DeepSeek-V3 shatters these barriers. This isn’t just another incremental improvement. DeepSeek-V3 represents a fundamental reimagining of how AI can be developed, deployed, and leveraged across industries:
- Cost Efficiency: Training at just $5.6 million (compared to $50+ million for competitors)
- Flexible Architecture: Activating only the most relevant AI “experts” for each task
- Flexibility with Open Weights: Enabling unprecedented customization and control.
DeepSeek-V3 is a strategic inflection point for businesses ready to leapfrog their competition.
By democratizing access to advanced AI, this model empowers organizations to:
- Reduce operational costs
- Accelerate innovation
- Create more intelligent, responsive systems
- Compete on a global technological stage
The Science Behind DeepSeek-V3
In the following sections, we’ll dive deep into the scientific innovations and practical implications of DeepSeek-V3 – showing why this isn’t just another AI model, but a blueprint for the future of enterprise technology.
Model tl;dr;
- Scalability: Unlike models like GPT-4 or LLaMA 3, which scale primarily through increasing parameter count, DeepSeek-V3 demonstrates that selective activation can achieve comparable or superior performance with fewer active parameters.
- Efficiency: The MoE architecture allows DeepSeek-V3 to be trained in just 2.79 million GPU hours, less than 1/10 the time required for LLaMA 3.1 405B. This represents a significant advancement in training efficiency.
- Cost-Effectiveness: With a training cost of only $5.6 million, DeepSeek-V3 challenges the notion that state-of-the-art performance requires massive financial investment.
- Attention Mechanism: While models like GPT-4 use variants of self-attention, DeepSeek-V3’s Multi-Head Latent Attention offers a more memory-efficient alternative without sacrificing performance.
- Training Objectives: The Multi-Token Prediction approach differs from the standard next-token prediction used in most autoregressive LLMs, potentially offering better learning dynamics.
- Precision: The use of FP8 mixed precision training pushes the boundaries of low-precision computation in LLMs, going beyond the FP16 commonly used in models like GPT-3 and LLaMA.
Key Features and Innovations
Mixture-of-Experts (MoE) Architecture
Mixture of Experts (MoE) is an AI architecture that enhances efficiency by dividing a large model into smaller, specialized sub-networks called “experts.” A gating network directs inputs to the most relevant experts, ensuring that only a subset of them is activated for each task. This selective activation reduces computational costs while maintaining high performance. Each expert focuses on specific patterns in the data. For example, in a language model, one expert might handle syntax, while another deals with semantics.
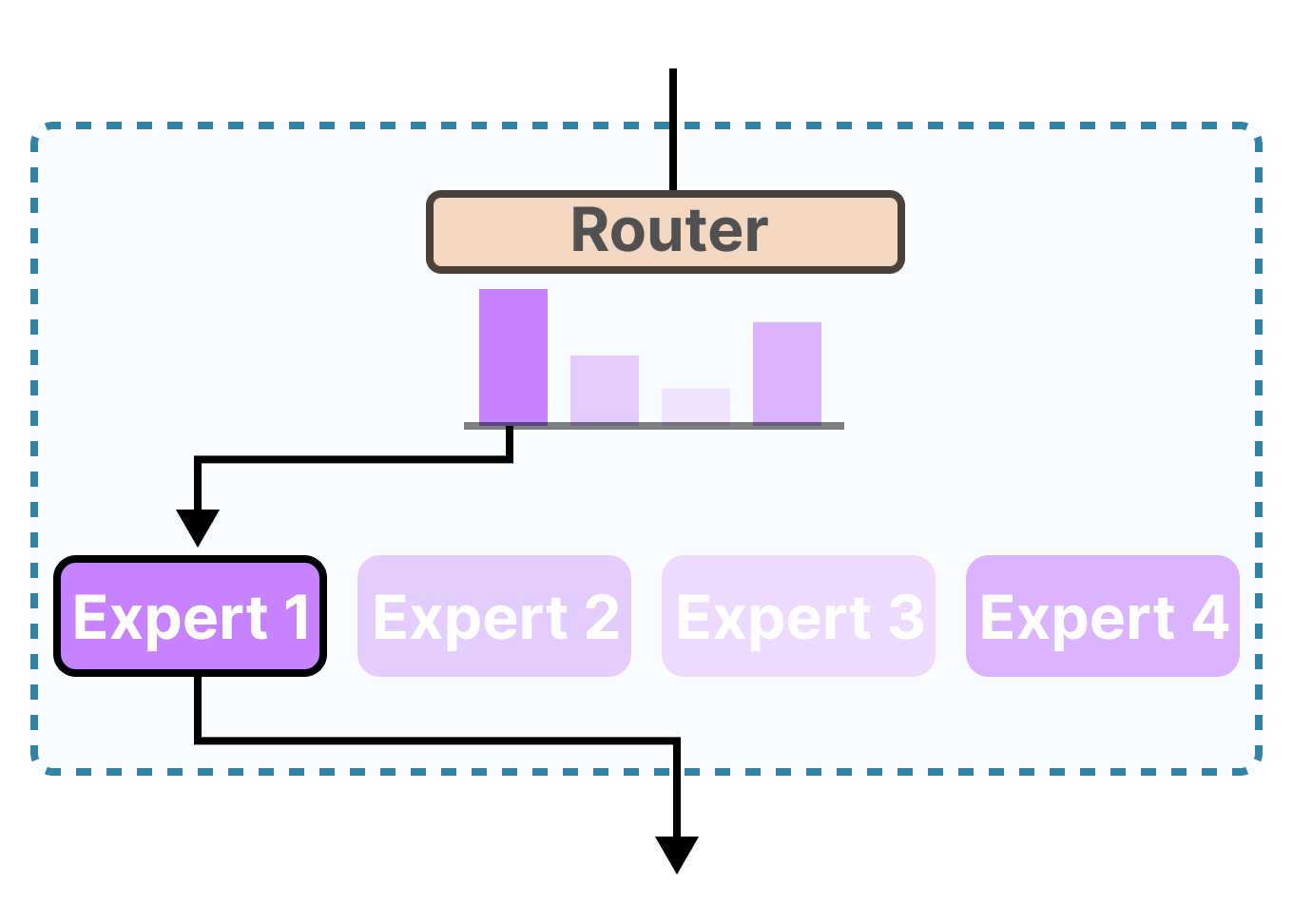
Figure: A toy illustration of how the router (gate network) selects the expert(s) best suited for a given input. The expert handles specific tokens in specific contexts. DeepSeekMoE enhances the MoE architecture by introducing shared experts—sub-networks that remain active for all inputs to capture common knowledge across tasks. These shared experts reduce redundancy among routed experts, improving computational efficiency and model consistency. DeepSeekMoE architecture employs 256 routed experts and 1 shared expert, where each token interacts with only 8 specialized experts plus the shared expert – effectively using about 5% of total parameters per token.
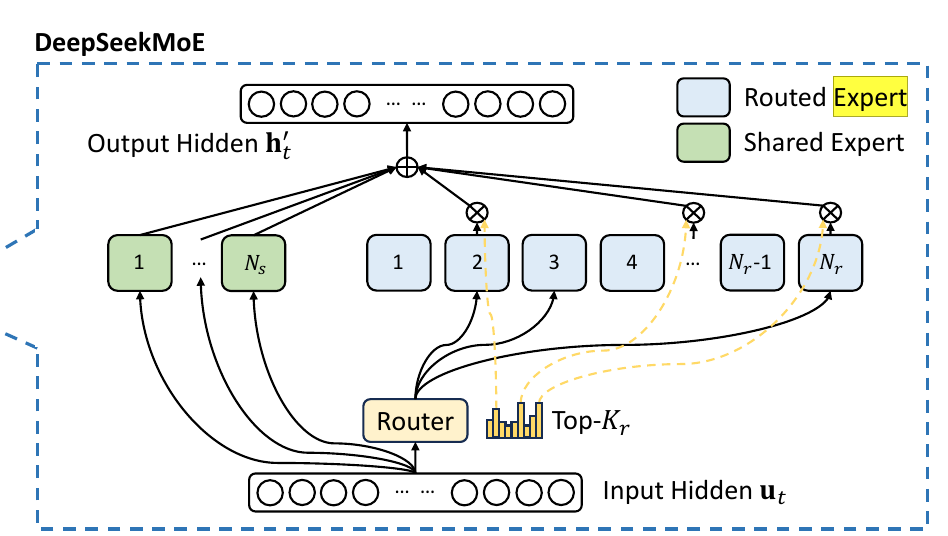
Figure: An Illustration of DeepSeek-V3’s MoE design, where only a subset of experts is activated per token, optimizing efficiency and reducing computational costs. This architectural innovation translates to substantial cost savings and enhanced scalability, making advanced AI capabilities more accessible to a wider range of users and applications.
FP8 Mixed Precision Training
Mixed precision training combines high (32-bit) and low (8-bit or 16-bit) precision to enhance efficiency. Lower precision accelerates most computations, while higher precision is reserved for critical operations like loss calculation and gradient updates to ensure stability.
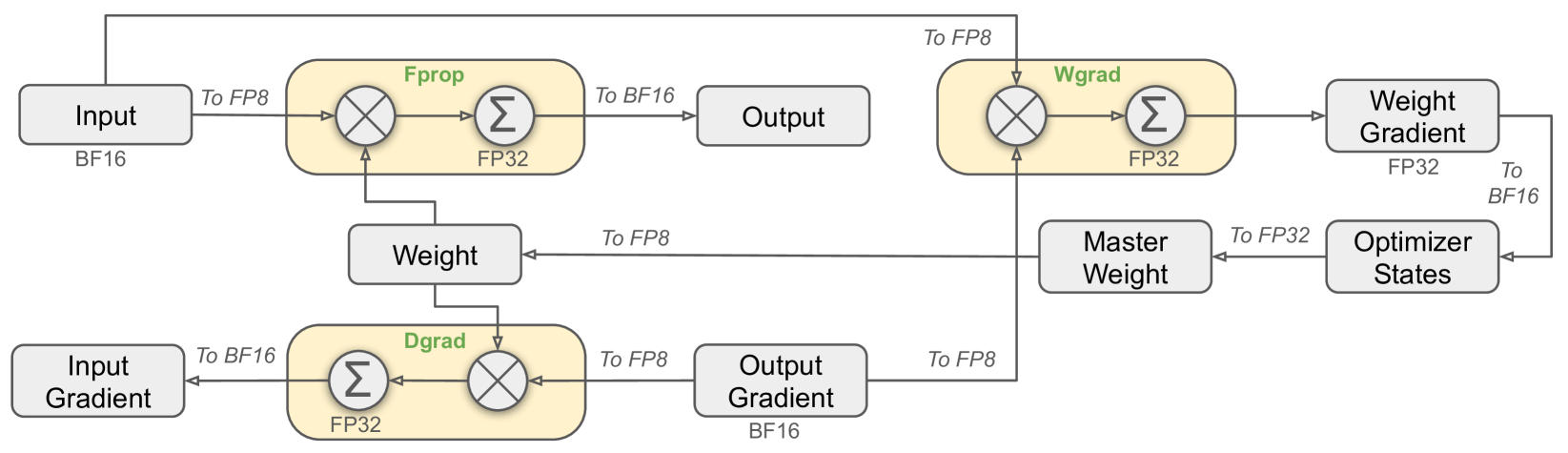
Figure: This architecture diagram shows the data flow between different components including Input (BF16), Weight, Output, and Gradient processing blocks, with various precision conversions (FP8, FP32, BF16) occurring throughout the pipeline. DeepSeek-V3 employs FP8 precision, reducing memory and computational demands compared to FP16 or FP32. This enables efficient training on fewer GPUs while preserving high accuracy.
Multi-Head Latent Attention (MLA)
DeepSeek-V3 introduces Multi-Head Latent Attention (MLA) as a more efficient way to manage attention in large language models. Traditional models like GPT-4 use self-attention, where every word (or token) in a sentence attends to every other word. While effective, this approach requires significant memory and computation, especially for long inputs.
MLA optimizes this process by compressing attention representations before expanding them again when needed. Instead of storing and processing a large amount of information at once, MLA uses a smaller, more memory-efficient representation to capture relationships between words. This reduces computational overhead without sacrificing performance.
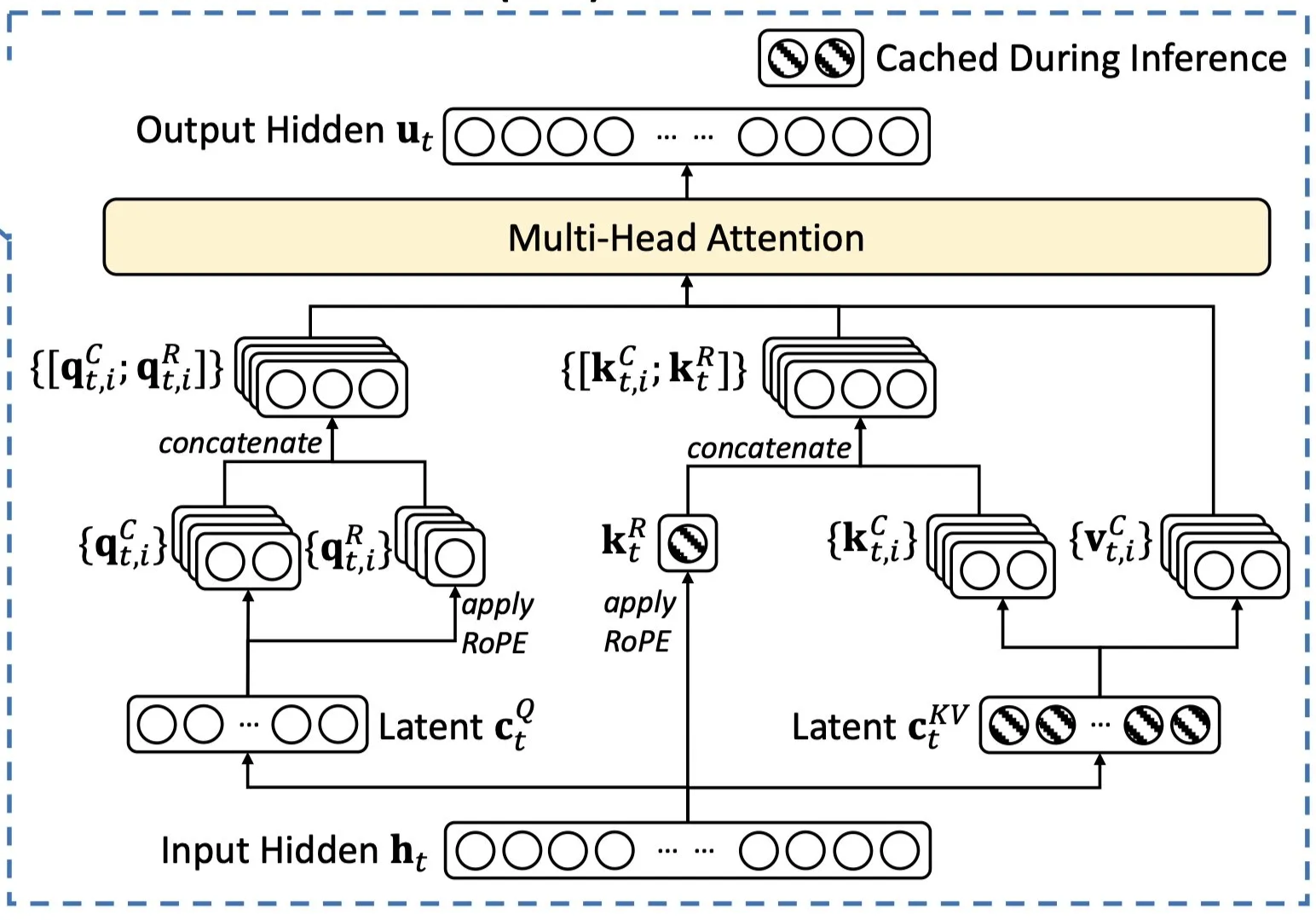
Figure: Visualization of MLA’s compressed latent representation, improving memory efficiency while maintaining robust attention across inputs. Metaphorically speaking, MLA is like summarizing key details before making a decision. Imagine reading a long report—rather than memorizing every word, you might note key themes and refer back to specific details only when necessary. Similarly, MLA enables DeepSeek-V3 to process complex inputs more efficiently while preserving accuracy.
By reducing the memory burden and improving processing speed, MLA helps DeepSeek-V3 scale more effectively without requiring excessive computational resources.
Auxiliary-loss-free load balancing
This novel approach dynamically adjusts expert-wise biases before routing, ensuring balanced utilization without interference gradients. Tokens are assigned to a select number of experts (Top-K) based on affinity scores, with biases adjusted to prevent overload—reducing bias for overused experts and increasing it for underused ones. This approach maintains consistent load distribution without the performance trade-offs of traditional auxiliary losses, enabling superior results across tasks while optimizing computational efficiency.
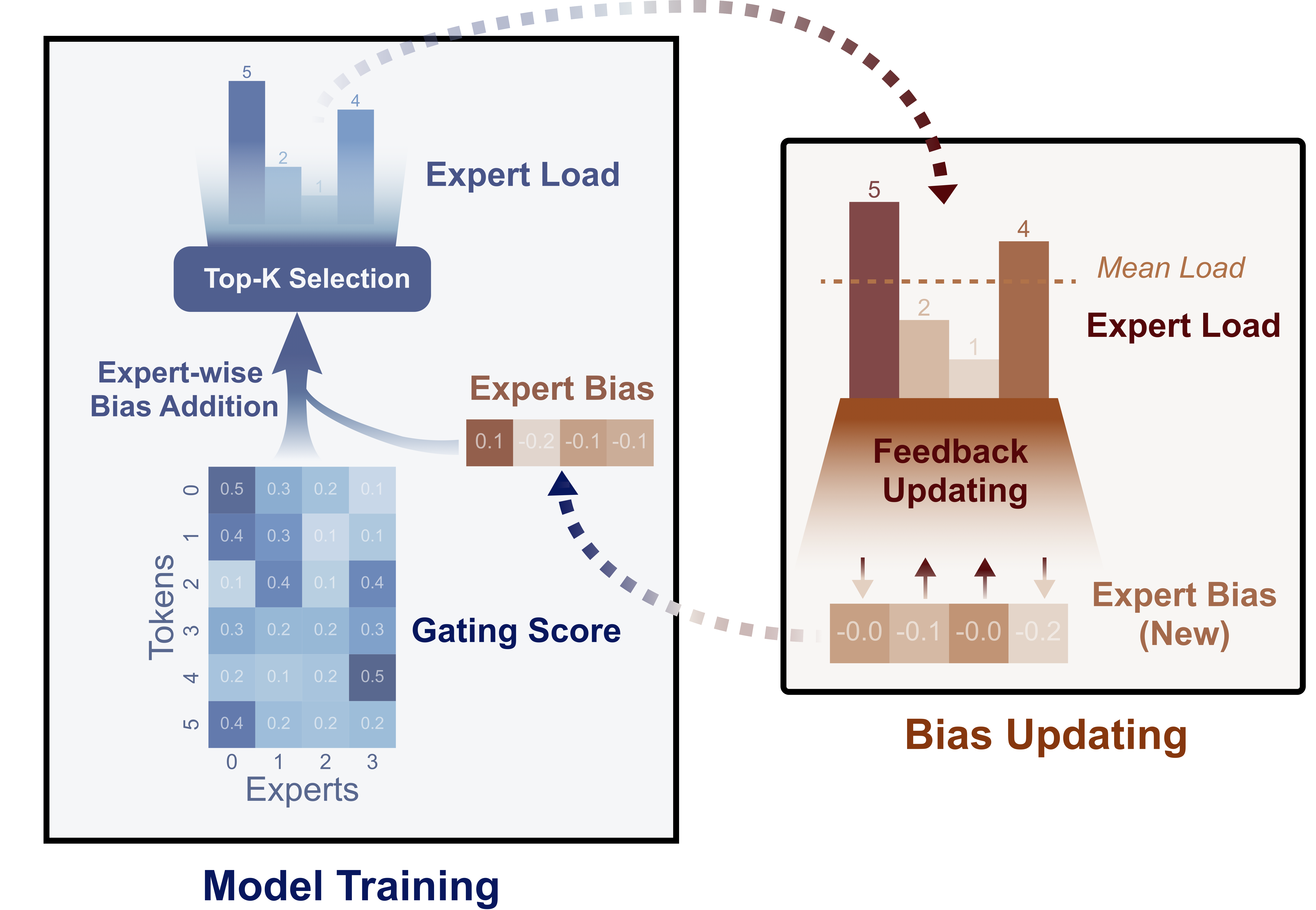
Figure: Diagram of dynamic expert assignment, showing how DeepSeek-V3 prevents overloading by adjusting biases before routing tokens to experts. Multi-Token Prediction (MTP)
DeepSeek-V3 utilizes Multi-Token Prediction (MTP), training the model to predict multiple future tokens simultaneously. This approach densifies training signals, improves efficiency, and enhances performance on complex tasks like coding and math. MTP enables faster inference and optimizes memory usage, proving particularly effective for larger models. Trained on 14.8 trillion tokens, DeepSeek-V3 achieves state-of-the-art results, outperforming traditional next-token prediction models on benchmarks like HumanEval and MBPP.
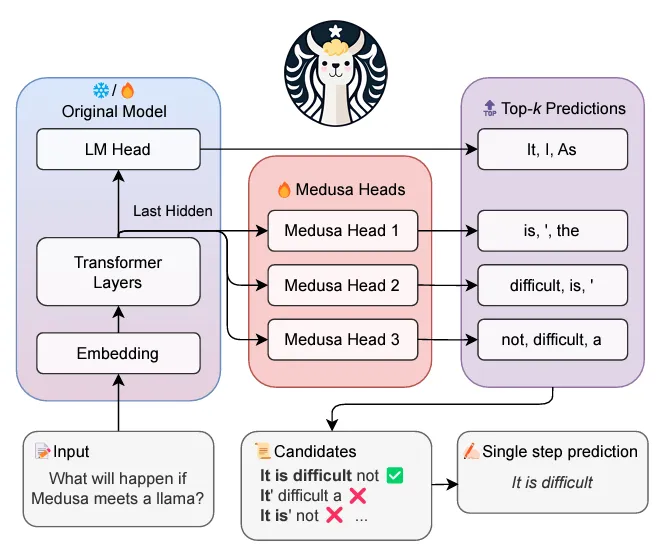
Figure: This figure illustrates DeepSeek-V3's parallel token prediction architecture. The model processes input through multiple "Medusa heads" that can simultaneously predict different sequences of tokens. While the original model head predicts "It, I, As", three additional Medusa heads generate different token combinations like "is, ', the" and "difficult, is, '", allowing for efficient parallel processing. This multi-head approach enables the model to predict multiple tokens in a single step, enhancing inference speed and computational efficiency.
Benchmarking
DeepSeek-V3 demonstrates exceptional capabilities across a wide range of applications:
Coding: Achieved a 73.78% score on HumanEval, rivaling specialized coding models
Mathematical Reasoning: Scored 84.1% on GSM8K, showcasing strong problem-solving abilities.
General NLP Tasks: Outperformed models like LLaMA 3.1 and GPT-NeoX in summarization, question answering, and sentiment analysis.
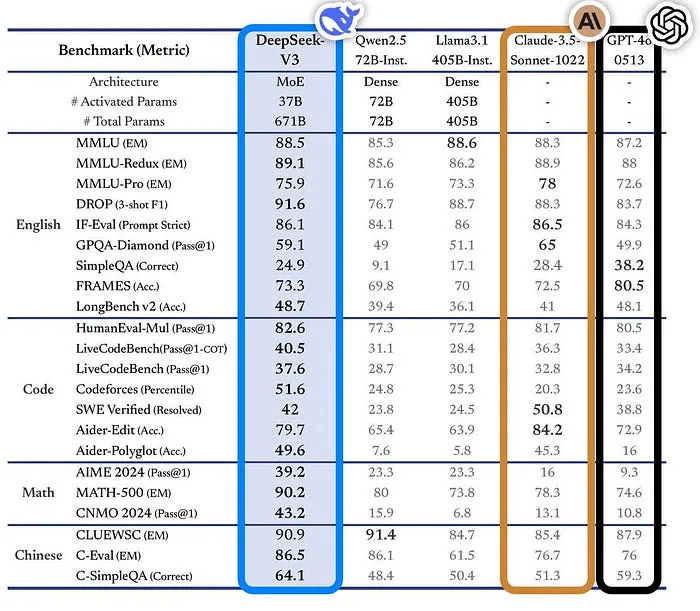
Figure: Performance comparison of DeepSeek-V3 against models like LLaMA 3.1 and GPT-4 across tasks such as NLP, coding, and mathematical reasoning.
These benchmarks establish DeepSeek-V3 as a strong competitor to both open-weight and proprietary models, including GPT-4 and Claude Sonnet.
Cost-Efficiency and Accessibility
One of DeepSeek-V3’s most significant advantages is its cost-effectiveness:
- Training Cost: Approximately $5.6 million, compared to $50+ million for models like OpenAI’s GPT-4.
- API Pricing: $0.55 per million input tokens and $0.75 per million output tokens, significantly cheaper than competitors. OpenAI’s GPT-4 costs approximately $15+ per million tokens (input/output combined).
Open Weights: Balancing Flexibility and Ethical Responsibility
DeepSeek-V3’s open weights give enterprises greater flexibility and control over AI fine-tuning and deployment. However, they also introduce important security and ethical considerations that businesses must address.
- Security Risks and Model Exploitation: Open-weight models can be modified to bypass built-in safeguards, increasing the risk of jailbreaking—where users manipulate the model to generate harmful or unethical content. For instance, previous open-weight models have been fine-tuned to spread disinformation, evade content filters, or automate phishing attacks. To mitigate these risks, enterprises must enforce rigorous monitoring and access controls.
- Compliance and Legal Responsibilities: Since DeepSeek-V3 can be fine-tuned on proprietary or sensitive data, organizations bear full responsibility for ensuring compliance with data privacy laws (e.g., GDPR, CCPA) and intellectual property protections. Without proper vetting, AI-generated outputs could inadvertently violate copyright laws or expose confidential information.
- Mitigation Strategies: To manage these risks, enterprises should:
- Implement strict access policies to control how the model is used internally.
- Regularly audit AI-generated outputs to identify potential biases or harmful responses.
- Conduct red-teaming exercises—where security experts actively test for vulnerabilities—to strengthen safeguards.
- Use responsible fine-tuning practices, ensuring that training data aligns with ethical guidelines and regulatory standards.
Conclusion
DeepSeek-V3 represents a paradigm shift in LLM development, offering:
- Unprecedented cost-efficiency through sparse activation
- State-of-the-art performance across diverse tasks
- Publicly available model weights with integrated ethical safeguards.
- Extended context processing (up to 128K tokens)
For AI researchers, DeepSeek-V3 opens new avenues for exploring efficient model architectures and training techniques. For enterprise users, it provides a powerful, cost-effective solution for integrating advanced AI capabilities into their operations. As DeepSeek-V3 continues to evolve, it has the potential to reshape the AI landscape, making advanced language models more accessible, efficient, and ethically aligned than ever before.
References
- DeepSeek-V3 Technical Report https://arxiv.org/pdf/2412.19437v1
- https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
- https://rohanpaul.substack.com/p/deepseek-v3-technical-report-they
- https://ai.gopubby.com/deepseek-v2-an-efficient-and-economical-mixture-of-experts-llm-ed9690ad1552
- https://huggingface.co/blog/wolfram/llm-comparison-test-2025-01-02
- https://www.infoq.com/news/2025/01/deepseek-v3-llm/
- https://www.geeky-gadgets.com/deepseek-v3-ai/