Introduction
The “Attention is All You Need” paper by Vaswani et al. introduced the Transformer architecture, which has become a foundational model for many natural language processing (NLP) and other sequence-to-sequence tasks. Transformers are neural networks that learn context and understanding through sequential data analysis.
The Transformer models use a modern and evolving mathematical techniques set, generally known as attention or self-attention. This self-attention mechanism lets each word in the sequence consider the entire context of the sentence, rather than just the words that came before it. This is akin to a person paying varying degrees of attention to different parts of a conversation.
Transformer Architecture: Workflow
The below summarizes the workflow of Transformers, representing the key components involved in the process.
- Input Embeddings and Positional Encoding
- Input Embeddings: The input sequence (e.g., words in a sentence) is first converted into numerical vector representations called embeddings.
- Positional Encoding:
- Since the Transformer does not use recurrence or convolutions, it needs a way to incorporate the position of each word in the sequence. This is done by adding a unique positional encoding vector to each word embedding.
- Positional encodings always stay the same and are not learned. In a given sentence, “The cat chased the mouse”, the word ’the’ in this sentence will yield two slightly different embeddings.
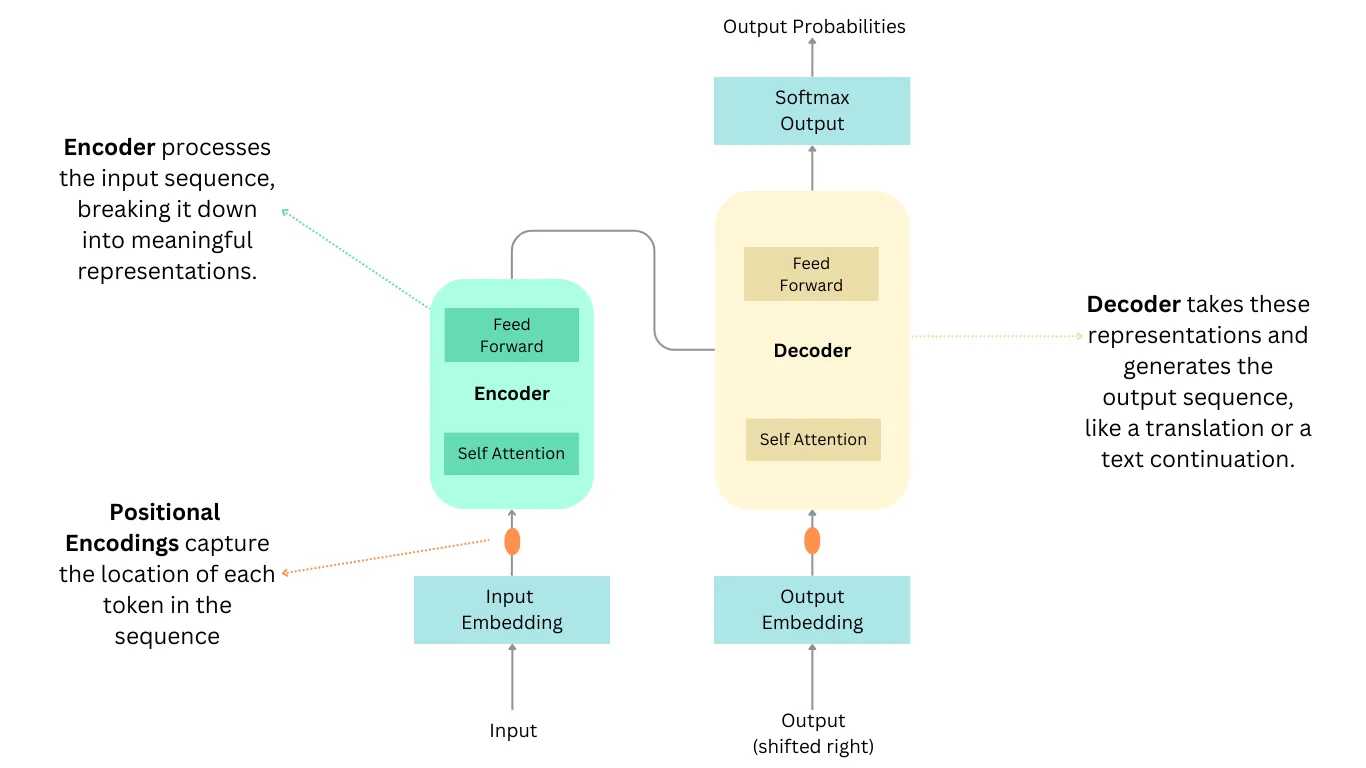
Encoder
- The encoder consists of multiple identical layers, each containing two sub-layers:
- Multi-Head Self-Attention: This allows each word to attend to all other words in the input sequence to compute representations capturing context and long-range dependencies
- Feed-Forward Neural Network: This applies a simple neural network to each position independently to further refine the representations.
- The output of the encoder is not a single vector, but rather a sequence of contextualized vector representations, one for each token in the input sequence.
- This contextualized vector represenation sequence for each token encodes the context of the full input sequence, taking into account surrounding words and relationships, allowing it to capture long-range dependencies efficiently.
- This rich representation of the input sequence is then passed to the decoder component, which uses it to generate the output sequence (e.g., translation, summary)
- The encoder consists of multiple identical layers, each containing two sub-layers:
Decoder
- The decoder also consists of multiple identical layers with two sub-layers:
- Masked Multi-Head Attention: This allows attending to previous positions in the output sequence for autoregressive generation.
- Encoder-Decoder Attention: This attends to the encoder output representations to integrate information from the input sequence
- Feed-Forward Neural Network: Similar to the encoder’s feed-forward network.
- The decoder generates the output sequence one token at a time, using the representations from the encoder and its own previous predictions.
- The decoder also consists of multiple identical layers with two sub-layers:
The key innovation of the Transformer is its reliance on attention mechanisms, which allow it to weigh and combine information from different parts of the input sequence when computing representations. This eliminates the need for recurrence or convolutions, enabling parallelization and efficient processing of long sequences.
Why transformers?
The transformer architecture solved several key issues present in previous architectures like Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) for sequence-to-sequence tasks.
- Parallelization and Training Efficiency:
- Transformers can process input sequences in parallel, enabling much faster training compared to sequential processing in RNNs.
- Transformers mitigate the vanishing gradient problem, which affects the training of deep RNNs, by avoiding recursive computations and using residual connections.
- Transformers achieved very good results in a fraction of the training time required for previous architectures like encoder-decoders with RNNs.
- Capturing Long-Range Dependencies:
- The self-attention mechanism in transformers allows capturing long-range dependencies and relationships between tokens in the input sequence more effectively than RNNs.
- RNNs struggled with long sequences as they had to process tokens sequentially, forgetting earlier information.
- Scalability and Model Size:
- Transformer models can be scaled up to very large sizes with billions of parameters, enabling better performance.
- Previous architectures like RNNs were difficult to scale and parallelize, limiting their size and performance.
- Flexibility and Adaptability:
- The transformer architecture is highly flexible and has been adapted for various tasks beyond machine translation, like text summarization, question answering, and language generation.
- Its self-attention mechanism makes it suitable for modeling different types of sequential data, not just text.
- Interpretability and Visualization:
- The attention mechanism in transformers provides some interpretability by revealing which parts of the input sequence the model attends to when generating output tokens.
- This interpretability is more challenging to achieve with the internal representations of RNNs.
Transformer Architecture in detail
The Encoder
Step 1: Input Embeddings
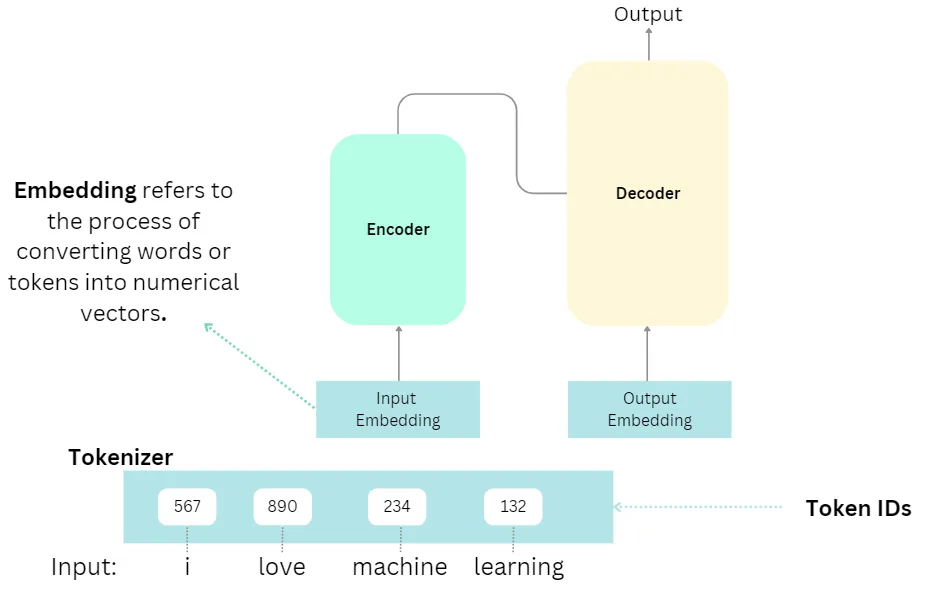
The embedding happens only in the bottom-most encoder. The encoder begins by converting input tokens - words or subwords - into vectors using embedding layers.These word vectors are often pre-trained on vast text corpora and capture semantic relationships between words.
These word vectors pass through an “embedding layer” in the model. This layer acts as a lookup table, associating each word with its corresponding vector.
Step 2: Positional Encoding
Step 3: Stack of Encoder Layers
Step 3.1: Multi-Headed Self-Attention Mechanism
Step 3.2: Normalization and Residual Connections
Step 3.3: Feed-Forward Neural Network
Step 4: Output of the Encoder
The Decoder
Step 1: Output Embeddings
Step 2: Positional Encoding
Step 3: Stack of Decoder Layers
Step 3.1: Masked Self-Attention Mechanism
Step 3.2: Encoder-Decoder Multi-Head Attention or Cross Attention
Step 3.3: Feed-Forward Neural Network
Step 4: Linear Classifier and Softmax for Generating Output Probabilities
Real-life Transformer Model
References:
- The Transformer Architecture: A Visual Guide, https://www.hendrik-erz.de/post/the-transformer-architecture-a-visual-guide-pdf-download
- Transformer Architecture Simplified, https://medium.com/@tech-gumptions/transformer-architecture-simplified-3fb501d461c8
- The Illustrated Transformer, https://jalammar.github.io/illustrated-transformer/
- The Transformer Family, https://lilianweng.github.io/posts/2020-04-07-the-transformer-family/